

Uczenie maszynowe w archeologii staje się coraz bardziej popularne, oferując nowe możliwości analizy dużych zbiorów danych i odkrywania ukrytych wzorców. To jednak już sam proces opisu i przygotowania danych jest często znacznie bardziej czasochłonny niż praca wybranych algorytmów. Już dziś, w trakcie procesu przygotowania właściwych opisów, możemy dostrzec potrzebę współpracy dobrze wyszkolonych archeologów i zaawansowanych specjalistów zajmujących się sztuczną inteligencją. Wierzymy, że tylko takie zespoły będą w stanie skutecznie wykorzystać nowe możliwości i osiągnąć wartościowe wyniki.
Fascynacja możliwościami oferowanymi przez sztuczną inteligencję udzieliła się w ostatnich latach również badaczom przeszłości. Specyfika danych archeologicznych, w tym częste występowanie dużych kolekcji źródeł o bardzo podobnych parametrach, otwiera nowe pola do wykorzystania nieskończonego potencjału, jaki niesie za sobą uczenie maszynowe czy sieci neuronowe. Jednak proces opisu i przygotowania danych bywa znacznie bardziej czasochłonny niż praca algorytmów. Dlatego już teraz tak ważna i potrzebna jest współpraca pomiędzy specjalistami do spraw sztucznej inteligencji a dobrze wyszkolonymi archeologami. Wierzymy, że tylko takie zespoły będą w stanie skutecznie wykorzystać te nowe możliwości i osiągnąć cenne rezultaty.
Niesamowite możliwości SI
Obecnie sztuczna inteligencja stanowi jeden z gorących tematów nie tylko wśród serwisów technologicznych, ale także badaczy wielu dziedzin nauki. Niesamowite możliwości SI (w angielskim AI) powoli zaczynają obrastać legendami. Paradoksalnie jednak publikacji naukowych opisujących skuteczne zastosowanie tych technologii w archeologii nie ma aż tak wiele, jak mogłoby się wydawać. Owszem, bez trudu można znaleźć wiele artykułów opisujących jej potencjalne możliwości, ale nadal dużo trudniej o przykłady praktycznego zastosowania tej technologii i wniosków wyciągniętych dzięki jej wykorzystaniu.
Sztuczna inteligencja to termin bardzo pojemny, o dosyć niejasnych granicach. W tym tekście skupimy się jednak na specyficznym obszarze tego zagadnienia – uczeniu maszynowym i sieciach neuronowych, które już na pierwszy rzut oka mają potencjał do wykorzystania przez archeologów.
Uczenie maszynowe w archeologii
Na pytanie, gdzie jest miejsce sieci neuronowych w archeologii, odpowiedź brzmi – wszędzie tam, gdzie mamy do czynienia z dużymi zbiorami zunifikowanych danych. Czyli im więcej zebranych danych przyporządkowanych do przejrzystych kategorii i posiadających określone cechy, tym lepiej sprawdzić się może uczenie maszynowe. Ważne jest, aby czas potrzebny na tworzenie, naukę i zastosowanie sieci neuronowej był znacząco krótszy niż wykonanie danego zadania manualnie.
W archeologii znalezienie powtarzalności i dużych zbiorów danych nie stanowi większego problemu. Te dwie cechy – podobieństwo elementów i rozmiar zbiorów – od zawsze były podstawą do budowy typologii i kluczem do zrozumienia badanego materiału zabytkowego.
Oczywiście zdarzają się sytuacje, kiedy brakuje nam danych. Pewien typ zabytku może być zbyt rzadki, by łatwo było go właściwie klasyfikować. Albo nasze rozpoznanie stanowisk danej kultury archeologicznej jest na tyle niewystarczające, że brakuje podstaw, do wyciągnięcia wiarygodnych wniosków. Mimo to, dla wielu archeologów praca nad dużymi zbiorami zabytków to codzienność. Przyłożenie suwmiarki do tysięcy fragmentów ceramiki lub analiza danych wysokościowych z setek mielerzy może dostarczyć informacji ujawniających pewne, nieoczywiste reguły.
W poszukiwaniu metod automatyzacji
Wraz z postępującą cyfryzacją nauki, a także stopniowym wdrażaniem kolejnych metod cyfrowych, rozrost baz danych znacząco przyspieszył. W niektórych obszarach zainteresowań badaczy spotykamy się więc z sytuacją, w której ogrom informacji przerasta możliwości pracujących nad nimi ludzi.
W odpowiedzi na to, przez kilkadziesiąt lat, jeszcze przed gwałtownym rozwojem metod związanych ze sztuczną inteligencją, archeolodzy szukali w technikach informatycznych sposobów automatyzacji swojej pracy. Celem było odkrycie pewnych zasad i stworzenie algorytmów wykorzystujących zauważane przez badaczy podobieństwa w analizowanym materiale.
Cała idea uczenia maszynowego opiera się właśnie na wykorzystaniu algorytmów. Te generują modele matematyczne na podstawie dostarczonych danych, w celu podejmowania decyzji i/lub ich grupowania. W zasadzie, w bardzo uproszczonej formie, można przyrównać to do programowania bez użycia żadnego konkretnego języka programowania. Badacz wprowadza dane i nadaje im odpowiednie wagi, tym samym poniekąd tworząc podstawy do działania programu. Sieć neuronowa następnie „uczy się” rozpoznawać konkretne cechy oraz wzorce w danych wejściowych. Na ich podstawie podejmuje decyzję lub tworzy grupę. Największa przewaga sieci neuronowych polega na możliwości przetwarzania ogromnych ilości informacji w krótkim czasie. Świadomość ograniczeń, jakie stoją przed tą technologią jest jednak kluczem do jej prawidłowego wykorzystania.
Przykłady zastosowania SI
Uczenie maszynowe należy podzielić na nadzorowane i nienadzorowane. W uczeniu nadzorowanym model wie, do czego ma dążyć, czyli dostarczamy mu dane i prawidłowe wyniki, a on szuka zależności między nimi. W uczeniu nienadzorowanym nie znamy wartości, do jakich dążymy, czyli dostarczamy modelowi dane, a on ma je podzielić na podstawie podobieństw, które zauważy. Klasycznym przykładem może być grupowanie danych, czyli podział ich na jednorodne grupy (tzw. klastry), co w archeologii można przyrównać do tworzenia typologii.
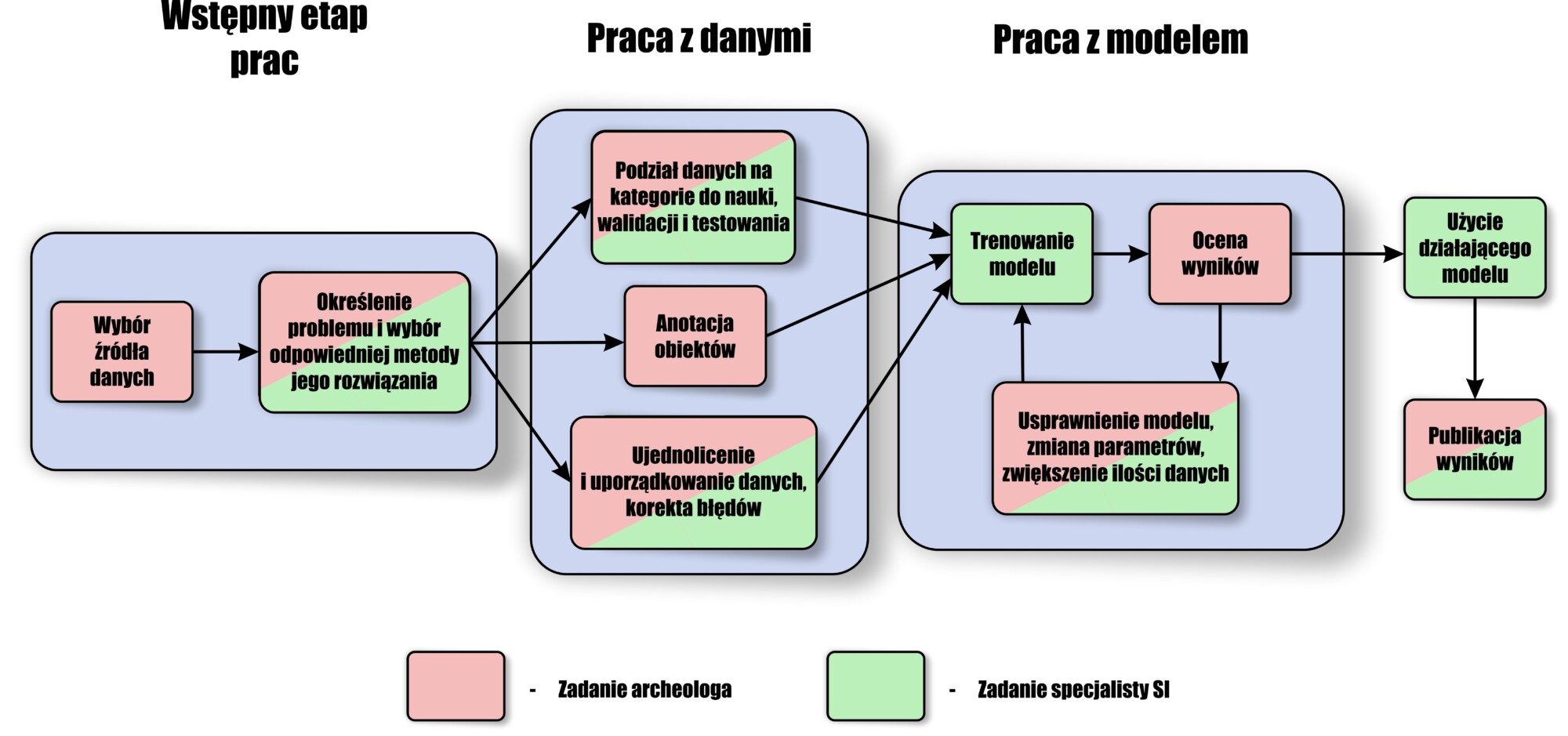
Aby uzmysłowić sobie jakie możliwości daje zastosowanie uczenia maszynowego w archeologii prześledzimy stworzony przez nas proces teledetekcji kurhanów na podstawie danych wysokościowych Niżu Polskiego, pochodzących z programu ISOK (Informatyczny System Osłony Kraju). Cały proces można podzielić na trzy główne części. Pierwszą jest zainicjowanie badań, określenie problemu i celu badawczego, wybór źródła danych, oraz dobór odpowiedniej technologii.
Drugą część stanowi przygotowanie danych do pracy. Stworzenie możliwie pełnej, kompletnej i spójnej bazy. Wybór danych do nauki, walidacji i testowania modelu. Jest to najbardziej żmudna i czasochłonna część całego projektu. Wymaga dużej dokładności i konsekwencji. W naszym przypadku obszary do nauki obejmowały 1300 kilometrów kwadratowych, które poddano dokładnej analizie i na których skrupulatnie oznaczyliśmy 1158 kurhanów. Dokładne oznaczenie (anotacja) wszystkich kurhanów na obszarach przeznaczonych do nauki jest kluczowe do prawidłowego działania modelu. Zauważyć tu należy kolejne ograniczenie uczenia maszynowego – każdy stworzony model będzie miał skuteczność nie wyższą niż ludzie tworzący anotację. Po dostarczeniu danych model będzie znacznie szybszy, odporny na „zmęczenie” czy „rozpraszanie”, które mogą utrudniać pracę człowiekowi.
Trzecią część stanowi praca z siecią neuronową. Wybraną wcześniej sieć uczymy i przygotowujemy wyniki, które następnie oceniane pod kątem trafności.
W takcie prac zbiór danych dzieli się na trzy kategorie – dane treningowe, walidacyjne i testowe. Dane treningowe służą do nauki algorytmu. Dane walidacyjne do sprawdzania jego skuteczności i dokładności w trakcie treningu oraz do oceny wydajności modelu po zakończeniu prac. Służą one także do uściślenia i poprawienia parametrów algorytmu, ewentualnych poprawek i zmian w danych treningowych. Danych testowych używa się do ostatecznego sprawdzenia sieci już po zakończeniu treningu. Co ważne zbiory tych danych są rozdzielone przez cały proces, tak aby model nie „widział” danych testowych przed ostatnim etapem prac. Tylko w ten sposób można uzyskać wiarygodną ocenę jego pracy.
Przedstawiony proces powtarzamy, aż do uzyskania satysfakcjonujących wyników. Tak w pewnym uproszczeniu zbudowany jest łańcuch operacji z użyciem sieci neuronowych.

© M. Jakubczak; na licencji CC BY 4.0
Uzyskanego efektu nadal nie możemy uznać za ostateczny. Stworzenie modelu, który sprawnie działałby na terenie całej Polski, wymaga od nas jeszcze wiele pracy. Niemniej na znacznych obszarach kraju wyniki są bardzo satysfakcjonujące. Na przykład na terenie województwa lubelskiego algorytm zaznaczył około 2500 potencjalnych kurhanów. Jednocześnie należy pamiętać, że sieć neuronowa nie interpretuje wyników, a jedynie szuka podobieństw, więc zaznacza wszystkie kopce i wzniesienia przypominające morfologicznie kurhany. Trzeba więc pamiętać, że każdy wykryty podczas teledetekcji obiekt archeologiczny, przed wpisaniem go do ogólnopolskich baz stanowisk archeologicznych, powinien zostać zweryfikowany w terenie. Możemy wyobrazić sobie, jak ogromnej pracy będzie to wymagać od badaczy i służb konserwatorskich. Pojawia nam się więc nowy problem, związany z liczbą stanowisk archeologicznych do weryfikacji, na który jak na razie nie mamy odpowiedzi.

© M. Leloch, M. Jakubczak; na licencji CC BY 4.0
Wyzwania w pracy z SI
Największymi wyzwaniami w pracy z uczeniem maszynowym, sieciami neuronowymi i ogólnie sztuczną inteligencją są przygotowanie danych oraz przypisanie im właściwych wartości. Ten etap jest niewątpliwie najbardziej czasochłonny. Archeolog musi zebrać bazę przykładów i opisujących je parametrów, a następnie, we współpracy ze specjalistą zajmującym się uczeniem maszynowym, dane te wykorzystać do tworzenia modelu. To prowadzi do kolejnej trudności, którą jest potrzeba znalezienia wspólnej płaszczyzny porozumienia pomiędzy archeologami, matematykami, czy specjalistami od data science i big data.
© M. Jakubczak, M. Leloch, na licencji CC BY 4.0
Gdzie jeszcze poza teledetekcją archeolodzy mogą wykorzystać sieci neuronowe? Odpowiedzi jest wiele: eksploracja tekstu (ang. text mining) w celu dokładniejszej i szybszej kwerendy, rozpoznawania zabytków, budowania typologii. Prowadzone są także badania nad użyciem tej metody w traseologii, czy przy budowie modeli prognostycznych. Wykorzystać możemy zarówno dane tekstowe, przestrzenne, tabele, a także obrazy rastrowe i wektorowe. Odpowiedź na pytanie, czy konkretnych danych można użyć, zależy od wielu czynników i wymaga indywidualnego podejścia w każdym przypadku i pytaniu badawczym.
Czy SI zastąpi archeologów?
Archeologia często szuka rozwiązań stawianych sobie problemów w metodach stosowanych w innych dziedzinach nauki. W odpowiedzi na tę potrzebę, poszczególni archeolodzy starają się, przynajmniej na podstawowym poziomie, wyspecjalizować w wykorzystaniu wybranych metod. Wraz z postępem nauki, komplikacją i zaawansowaniem niektórych technologii może to stawać się coraz trudniejsze. Tak może być również w przypadku zastosowania uczenia maszynowego i sieci neuronowych, gdzie to umiejętność komunikacji ze specjalistą będzie jedyną drogą do rozwiązania skomplikowanych problemów.
Czy powinniśmy bać się sztucznej inteligencji? Czy SI zastąpi archeologów? Na razie takiej groźby nie widać nawet na horyzoncie. Owszem ta technologia może przynieść wiele zmian, ale należy je rozpatrywać raczej w kategoriach nowych wyzwań oraz możliwości niż zagrożeń.
Artykuł ten można bezpłatnie przedrukować, ze zdjęciami, z podaniem źródła
Autorzy:
Michał Jakubczak – archeolog zatrudniony w Laboratorium Bio- i Archeometrii Instytutu Archeologii i Etnologii Polska Akademii Nauk w Warszawie. Kierownik projektu Długie domy jako element złożonego krajobrazu kulturowego. Rekonstrukcja sieci osadniczej Kujaw w 2 poł. V tys. cal BC z użyciem najnowszych metod teledetekcyjnych (NCN 2019/35/B/HS3/02941). Specjalizuje się teledetekcji archeologicznej, a także badaniach reliktów pradziejowych pól uprawnych. Uczestnik licznych projektów naukowych od wczesnego neolitu po I Wojnę Światową. W archeologii uwielbia szukać rozwiązań skomplikowanych i nietypowych problemów.
Academia: https://independent.academia.edu/Mjakubczak
ReasearchGate: https://www.researchgate.net/profile/Michal-Jakubczak
ORCID: https://orcid.org/0000-0002-1655-7124
Michał Leloch – archeolog, doktorant w Szkole Doktorskiej Nauk Humanistycznych Uniwersytetu Warszawskiego. Stypendysta w projekcie Wysokogórskie stanowiska ze sztuką naskalną w wąwozie Kyzyl Dara w Uzbekistanie (NCN 2019/35/O/HS3/03051). Specjalizuje się w badaniach sztuki naskalnej. Uczestnik projektów w Polsce, Uzbekistanie i Arabii Saudyjskiej. Największą satysfakcję daje mu pełen dzień marszu uwieńczony znalezieniem petroglifu przedstawiającego rydwan. Prywatnie właściciel psa Szurka i czterech roślin doniczkowych.
Academia: https://uw.academia.edu/Micha%C5%82Leloch
ReasearchGate: https://www.researchgate.net/profile/Michal-Leloch
ORCID: https://orcid.org/0000-0003-4916-7840
Redakcja: Julia M. Chyla
Do dalszej lektury:
Bickler, S. H. (2021). Machine Learning Arrives in Archaeology. Advances in Archaeological Practice, 9(2), 186–191. https://doi.org/10.1017/aap.2021.6
Argyrou, A. & Agapiou, A. (2022). A Review of Artificial Intelligence and Remote Sensing for Archaeological Research. Remote Sensing, 14(23). https://doi.org/10.3390/rs14236000
Trier, Ø. D., Reksten, J. H., & Løseth, K. (2021). Automated mapping of cultural heritage in Norway from airborne lidar data using faster R-CNN. International Journal of Applied Earth Observation and Geoinformation, 95. https://doi.org/10.1016/j.jag.2020.102241
der Vaart, W. V., Bonhage, A., Schneider, A., Ouimet, W., & Raab, T. (2023). Automated large-scale mapping and analysis of relict charcoal hearths in Connecticut (USA) using a Deep Learning YOLOv4 framework. Archaeological Prospection, 30(3), 251–266. https://doi.org/10.1002/arp.1889
Albrecht, C.M., Fisher, C., Freitag, M., Hamann, H.F., Pankanti, S., Pezzutti, F. & Rossi, F. (2019). Learning and recognising archeological features from lidar data. In 2019 IEEE International Conference on Big Data (Big Data), 5630-5636.
Freeland, T., Heung, B., Burley, D.V., Clark, G., Knudby, A. (2016). Automated feature extraction for prospection and analysis of monumental earthworks from aerial LiDAR in the Kingdom of Tonga. Journal of Archaeological Science, 69, 64-74. https://doi.org/10.1016/j.jas.2016.04.011
Berganzo-Besga, I., Orengo, H. A., Lumbreras, F., Carrero-Pazos, M., Fonte, J., Vilas-Estévez, B. (2021) Hybrid MSRM-Based Deep Learning and Multitemporal Sentinel 2-Based Machine Learning Algorithm Detects Near 10k Archaeological Tumuli in North-Western Iberia. Remote Sensing, 13. https://doi.org/10.3390/rs13204181
Olivier, M., Verschoofvan der Vaart, W. (2021). Implementing State of-the-Art Deep Learning Approaches for Archaeological Object Detection in Remotely—Sensed Data: The Results of Cross-Domain Collaboration. Journal of Computer Applications in Archaeology, 4, 274–289. https://doi.org/10.5334/jcaa.78
Jamil, A. H., Yakub, F., Azizul Azizan, A., Roslan, S. A., Zaki, S.A., Ahmad, S. A. (2022). A Review on Deep Learning Application for Detection of Archaeological Structures. Journal of Advanced Research in Applied Sciences and Engineering Technology, 26, 7–14. https://doi.org/10.37934/araset.26.1.714
Sakai, M., Lai, Y., Canales, J. O., Hayashi, M., Nomura, K. (2023). Accelerating the discovery of new Nasca geoglyphs using deep learning. Journal of Archaeological Science, 155. https://doi.org/10.1016/j.jas.2023.105777.
Orengo, H.A. & Garcia-Molsosa, A. (2019). A brave new world for archaeological survey: automated machine learning-based potsherd detection using high-resolution drone imagery. Journal of Archaeological Science, 112 https://doi.org/10.1016/j.jas.2019.105013
Okładka: Ilustracja wygenerowana w Midjourney, edycja w PS K.K.
Promt: Android siedzący na kurhanie i myślący. W stylu ekspresjonizmu malarskiego